Stable Diffusion完全ガイド|機能・使い方・プロンプトのコツ・商用利用
Stable Diffusionは、テキストプロンプトから高品質な画像を生成できる革新的なAIモデルとして広く注目を集めています。
2024年には柔軟なカスタマイズ性と強力なパフォーマンスを兼ね備えた「Stable Diffusion 3.5」シリーズが発表されており、今後もアップデートが見込まれる、今最も人気のある画像生成AIとなっております。
本記事では、Stable Diffusionの概要と特徴、使用方法、ライセンス、そして今後の展望について詳しく解説します。

AI導入.comを提供する株式会社FirstShift 代表取締役。トロント大学コンピューターサイエンス学科卒業。株式会社ANIFTYを創業後、世界初のブロックチェーンサービスを開発し、東証プライム上場企業に売却。その後、マッキンゼー・アンド・カンパニーにコンサルタントとして入社。マッキンゼー日本オフィス初の生成AIプロジェクトに従事後、株式会社FirstShiftを創業。
Stable Diffusionとは

Stable Diffusionは、Stability AI社が開発したテキスト入力(プロンプト)をもとに高精細な画像を自動生成するAIモデルです。
他のAI画像生成モデルよりも自由度が高く、写真、絵画、3Dレンダリング、線画など、多様なスタイルに対応できます。
Stable Diffusionの登場により、今やアーティストやデザイナーに限らず幅広いユーザーがクリエイティブな作品制作を気軽に実現可能となっています。
Stable Diffusionの主なモデル

Stable Diffusionはこれまでに数々の公式モデルをリリースしています。
以下に、Stable Diffusionの主要モデルを「モデル名」「パラメータ数」「リリース時期」「特徴」とともにまとめた表を作成しました。
| モデル名 | パラメータ数 | リリース時期 | 特徴 |
|---|---|---|---|
| Stable Diffusion 1.4 | 約8億 | 2022年8月 | 初期リリース。標準的な画像生成性能で、基本的なプロンプトに対応。 |
| Stable Diffusion 1.5 | 約9.8億 | 2022年10月 | 1.4の改良版。細部表現が強化され、よりシャープな画像生成が可能。 |
| Stable Diffusion 2.0 | 非公開 | 2022年11月 | フィルタリングされたデータセットで再トレーニング。新機能を導入。 |
| Stable Diffusion 2.1 | 非公開 | 2022年12月 | 2.0の改良版。プロンプト解釈と細部の描写力が向上。 |
| Stable Diffusion XL 1.0 (SDXL 1.0) | 約35億 | 2023年7月 | 高解像度・高精度な生成が可能。リアルな人物や複雑な構図に強い。 |
| SDXL Turbo | 非公開 | 2023年11月 | SDXL 1.0の蒸留版。少ない拡散ステップで高速な画像生成が可能。 |
| Stable Diffusion 3.0 | 8億〜80億 | 2024年2月(早期プレビュー) | 幅広いパラメータ数のモデルファミリー。 |
| Stable Diffusion 3.5 Large | 80億 | 2024年10月22日 | 高品質かつ迅速な適応性を持つ強力なモデル。1メガピクセルの解像度でプロフェッショナルな使用事例に最適。 |
| Stable Diffusion 3.5 Large Turbo | 非公開 | 2024年10月22日 | 3.5 Largeの蒸留版。4ステップで高品質な画像生成が可能で、高速性が特徴。 |
| Stable Diffusion 3.5 Medium | 25億 | 2024年10月29日 | 改良されたアーキテクチャとトレーニング方法により、カスタマイズのしやすさと画質を両立。コンシューマー向けハードウェアで動作し、0.25~2メガピクセルの解像度の画像を生成可能。 |
※一部のパラメータ数や特徴については公開情報が限られているため、詳細が不明な場合があります。
各モデルの特徴や派生モデルのおすすめ、モデルの選び方について知りたい方は、こちらの記事をご覧ください。

最新モデルStable Diffusion 3.5の概要

Stable Diffusion 3.5は2024年10月に公開された最新モデルです。
前バージョンまでの反省点とユーザーフィードバックを踏まえ、より使いやすく、より高品質な画像生成を目指して開発されました。ここでは最新版である3.5の開発背景と、モデルごとの特徴を解説します。
リリース背景
Stable Diffusion 3.5は2024年10月22日に公開されました。
前作「Stable Diffusion 3 Medium」の課題を見直し、時間をかけた最適化と改良が行われ、安定性・汎用性・カスタマイズ性のバランスを追求しています。
提供される3つのモデル
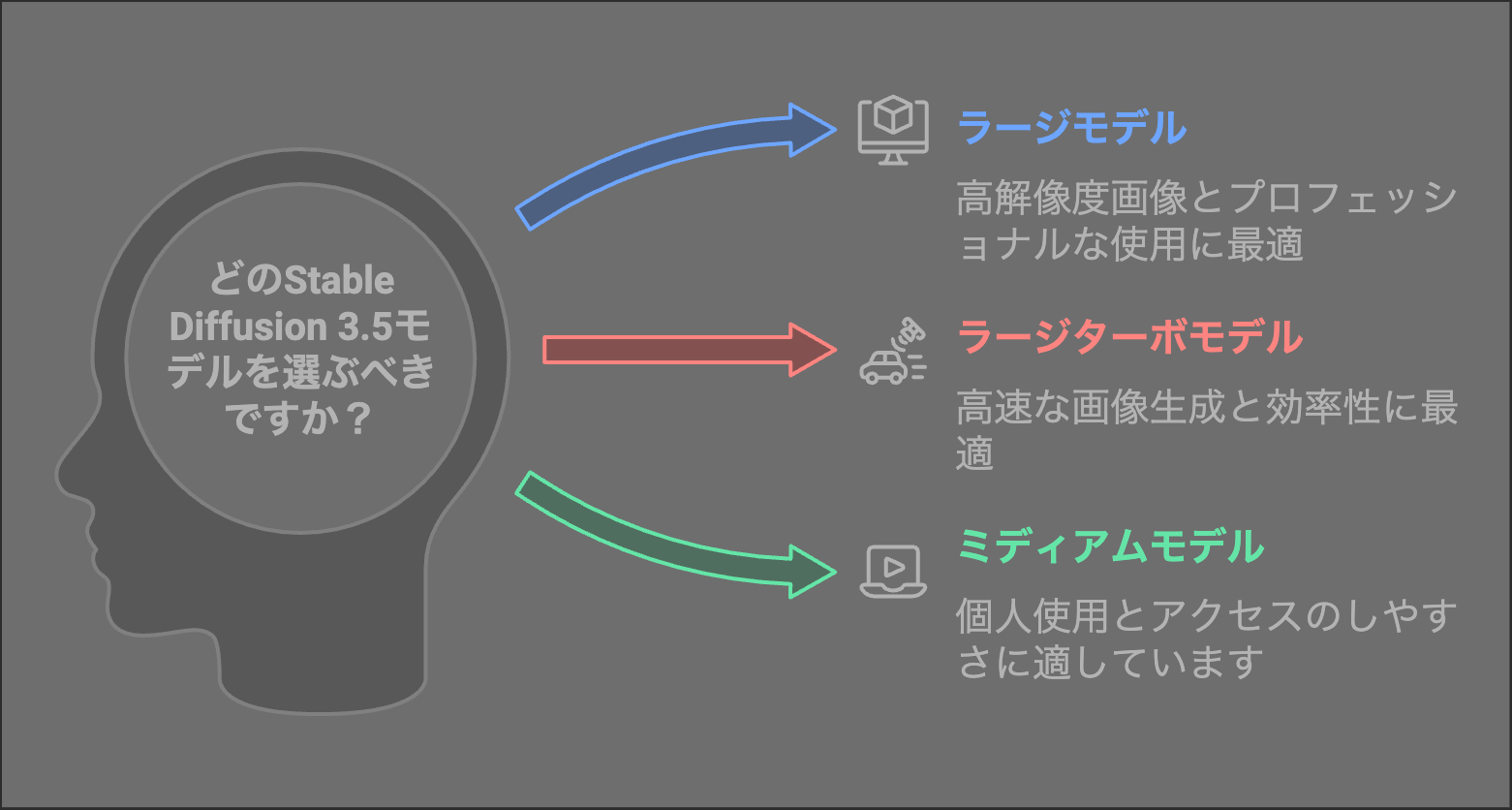
Stable Diffusion 3.5では3種類のモデルが提供されており、用途や目的に応じて使い分けることが可能です。
ここでは3種類のモデルの特徴をそれぞれ解説します。
Stable Diffusion 3.5 Large
約80億パラメータを持つ最強力モデル。1メガピクセル級の高解像度画像生成に対応し、専門クリエイターやビジネス向けに最適化されています。
Largeモデルは大規模パラメータによる圧倒的な表現力が特徴です。超高精細な画像生成が可能で、フォトリアルな風景、詳細なキャラクターデザイン、大規模な商用プロジェクトにも対応します。
Stable Diffusion 3.5 Large Turbo
Largeモデルを蒸留して高速化したモデル。わずか4ステップで高品質画像を生成でき、開発スピードや作業効率を重視するユーザーに適しています。
Large Turboモデルは、Largeの高品質を受け継ぎつつも圧倒的なスピードを実現しています。高速なプロトタイピングやアイデア出しの段階で、大幅な時間短縮が可能となります。
Stable Diffusion 3.5 Medium
約26億パラメータを持ち、消費者向けハードウェアでも気軽に動作可能な軽量モデル。即時性と扱いやすさを重視した構成で、個人ユーザーや小規模チームに理想的です。
Mediumモデルは小規模なパラメータ数で動作し、一般消費者向け環境でも容易に利用可能です。スタートアップや個人クリエイターが気軽に試せる手軽さが強みで、比較的軽量なGPUリソースでの運用が可能です。
Stable Diffusionの主な機能

Stable Diffusionは対応可能な機能や生成を年々増やしており、最新のStable Diffusionについては理想の画像を生成するための様々な制御機能を備えています。
ここでは最新のStable Diffusionの5つの機能・特徴を解説します。
多様な画風への対応
Stable Diffusion 3.5は、3Dレンダリングや写真風、イラスト、線画など、多種多様な画風に対応することが可能です。
ユーザーはテキストプロンプトで希望のスタイルを指定することで、理想のビジュアルを直感的に得ることができます。
多様性を尊重した画像生成
様々な肌の色や身体的特徴、文化的背景を持つキャラクター生成が可能で、多様性を尊重したクリエイティブな作品作りに活用できます。
高度な生成制御機能 (ControlNet対応予定)
今後のアップデートで、ControlNetなどの拡張機能への対応もされると言われています。プロンプトの意図をより細かく反映し、生成画像の属性を精密にコントロールすることで、制作プロセスを大幅に強化します。
画像中への文字描写能力
画像内へ特定のテキストやロゴを組み込むといった、高度な文字描写機能にも対応予定です。ブランド要素の挿入や説明的な要素の付加が容易になり、ビジネスシーンにも幅広く応用できます。
複数被写体の高精細表現
複数のオブジェクトや人物を一度に生成し、構図全体を洗練させることが可能です。複雑なシーン構築や物語性のあるイメージ作りに適しています。
Stable Diffusionの画像生成AIが使えるプラットホームサービス

Stable Diffusionを試しに使ってみたい方は、Webアプリケーション上に公開されている下記3つのサービスを活用すると効率的です。
Hugging Face

Hugging Faceは、Stable Diffusionなどの生成AIモデルを無料で試せるプラットフォームです。
ブラウザ上で動かせる「Spaces」やAPIを活用すれば、開発・検証もスムーズに行えます。オープンソース文化が強く、世界中の研究者や開発者が活発にモデルを共有しています。
Dream Studio

Dream Studioは、Stable Diffusionを開発したStability AIによる公式サービスで、高品質な画像生成が可能です。
使いやすいUIでプロンプト入力から生成まで簡単に行え、バージョン選択やサイズ変更にも対応。無料枠もあり、商用利用にも対応した有料プランが用意されています。
Mage

Mageは、ノーコードで誰でも簡単にStable Diffusionを使った画像生成ができるWebサービスです。
プロンプトを入力するだけで高精度な画像を作成可能で、作品の公開やSNS連携にも対応しています。直感的な操作性で初心者にもやさしく、無料・有料プランが選べます。
Stable Diffusionを用いた画像生成の3つのアプローチ
画像生成といえばテキストプロンプトで指示を書き、指示を元に生成する方法が一般的ですが、Stable Diffusionではそれ以外にも画像から画像を生成したり、動画素材の画風を変換したりと、様々なアプローチ方法を持っています。
ここでは具体的に3つの画像生成方法について解説します。
テキスト指示による画像生成 (txt2img)
最も一般的な方法が、テキストプロンプトを入力することでの画像生成です。
指示文に従ってモデルが自動的に画像を生成します。ユーザーは理想のイメージを自然言語で指定することで、手間なく欲しい画像を手に入れることができます。
一方でプロンプトの書き方で画像の質感は大きく異なってくるので、プロンプトの書き方のコツを押さえることが重要になります。プロンプトの書き方のコツはこの記事の後半で解説します。
既存画像を基にした新規画像生成 (img2img)
Stable Diffusionでは、既存の画像をもとに新たなイメージを生成する機能も利用可能です。
すでにある画像にフィルターをかけたりスタイルを変換するなど、用いたいオリジナル画像がある場合にはそれを活用したクリエイティブな画像生成を行うことができます。
一方で、使用する既存画像の著作権には注意する必要があります。
動画素材をアニメ風に変換
Stable Diffusion 3.5では、動画素材をアニメーション風スタイルに変換するといった高度な応用も可能です。
今後のアップデートやツール連携によって、動画制作のハードルが大幅に低下するでしょう。
Stable Diffusionはローカル/クラウドどちらを使うべき?

Stable Diffusionを動かすには、ローカルPCにダウンロードして使用する方法と、Web上でクラウドサービスのを利用する方法の2つがあります。
ローカル/クラウドそれぞれのメリット/デメリットを表でまとめました。
| ローカル | クラウド | |
|---|---|---|
| メリット | 制限なく使える\プライバシー保護\拡張機能を自由に導入しやすい | 初期準備が少ない\高性能GPUを必要な時だけ利用できる(Google ColabやAWSなど) |
| デメリット | 高スペックPCが必要\セットアップの手間やトラブルシュートが必要 | 利用制限やセッション切断のリスク\使うほど費用がかさむ\データ保存や利用規約に注意が必要 |
これらのメリットデメリットを踏まえ、ローカル/クラウドがそれぞれどのようなユーザーに適しているのか、解説します。
ローカルで使用するのが適しているケース
Stable Diffusionをローカルで使うのは、GPU搭載PCを持ち、生成画像の品質やプライバシーを重視するユーザーに向いています。
モデルや拡張機能を自由にカスタマイズできるため、プロンプトの微調整やLoRA、ControlNetなど高度な操作を行いたい中〜上級者に最適です。
ネット環境に依存せず、生成コストも抑えられるメリットがあります。
クラウドで使用するのが適しているケース
クラウド利用は、高性能なPCを持たない人や、インストールなしですぐに使いたい初心者に最適です。
DreamStudioやMageなどは直感的に使え、設定も簡単。PCに負荷をかけず、手軽に高品質な画像が得られます。
作業量が少なくスポット的に画像生成したい場合や、外出先・スマホからの利用にも便利です。
画像生成におけるプロンプトの書き方のコツ

画像生成のクオリティは、プロンプト(テキスト指示)次第で大きく左右されます。
思い通りの画像を生成するためのプロンプトのコツを、3つご紹介します。
可能な限り具体的に指示を書く
描きたいもののイメージを可能な限り具体的に書くことが重要です。詳細を入れることにより、自分の想像するS型に近いものを精度高く生成することが可能になります。
- 悪い例:「魔女」... 指示が少ないため、どのような格好で、
- 良い例:「岩の上に腰掛け、雷の魔法を放つ美しい女魔術師」
ネガティブプロンプトを活用する
Stable Diffusionでは、画像生成時に描いてほしくない要素を支持として書くことができます(ネガティブプロンプト)。
例としては下記のような指示をネガティブプロンプトの欄に書くことで、質の低い画像を避けることができます。
- Blurry ... ぼやけて不鮮明
- Law Quality... 質の低い画像・絵
- Deformed Hands ... 手の変形
指示キーワードの重みづけを行う
(keyword:1.3) のように丸括弧で強調し、 [keyword:0.7] で抑制するなど、プロンプト内で強弱を付けられます。
Stable Diffusionのプロンプトに関する詳細な解説はこちらの記事をご覧ください

Stable Diffusionの拡張機能・カスタマイズツール

Stable Diffusionにはコミュニティ発の多数の拡張機能や、カスタマイズツールがあります。
ここでは6つの拡張機能・カスタマイズツールを紹介します。
ControlNet
Control Netを用いると、輪郭やポーズなどの画像情報を参照し、構図を厳密に指定した上で画像生成が可能です。
たとえばOpenPose抽出を使い、写真のポーズを別キャラに流用できます。
LoRA (Low-Rank Adaptation)
基本モデルに差分だけ上乗せし、特定の絵柄やキャラクターを学習させ流ことができます。これをLoRAと呼びます。
ファイルサイズが小さく、複数を組み合わせて使いやすいのが特徴。
Textual Embeddings
ごく小容量の「単語ベクトル」を学習したファイルを導入し、新しい固有名詞やスタイルをモデルに覚えさせることができます。この仕組みをTexual Embeddingsと呼びます。
LoRAより軽量だが、表現力は限定的。
DreamBooth
数十枚程度の画像から特定人物やスタイルを学習し、モデルを再構築。
出力ファイルは大きくなるが再現性は高い。
Textual Inversion
新しい「単語」を覚えさせるようなイメージで、数KB~数百KBの埋め込みを学習。
固有名詞や限定的なスタイル追加に有効。
Stable Diffusion用GUIツールの比較

AUTOMATIC1111 Web UI
もっとも広く使われている定番ツール。拡張機能やアップデートが充実し、初心者から上級者まで利用者が多い。
InvokeAI
軽量最適化が進んだオープンソースUI。メモリ効率や安定性に優れ、キャンバス機能やノードベースの新GUIも取り入れている。
ComfyUI
ノードベースで高度な生成パイプラインを直感的に組めるUI。自由度が高い分、習熟にはややハードルがあるが、上級者向けに人気。
Stable Diffusionは商用利用可能?

Stable Diffusion自体はCreative ML OpenRAIL-Mライセンスが適用され、商用利用も基本的に可能ですが、「悪用禁止」など一定の倫理規定が含まれます。
また、派生モデル(二次創作モデルや特定絵師モデルなど)は、配布先のライセンス確認が重要です。商用不可のモデルを用いて生成された画像を使うと、トラブルに発展する可能性があります。さらに、著作権リスクや肖像権などにも配慮しましょう。法律的にグレーな部分も多く、特に実在人物の肖像や著名キャラクターに酷似した生成物を商用利用する際には、慎重な対応が求められます。
Stability AI Community Licenseの概要
Stable Diffusion 3.5は、Stability AI Community Licenseの下で提供され、ユーザーの規模や収益に応じたライセンス条件が適用されます。
無償利用条件と商用ライセンス
年間収入100万ドル未満の個人や団体は、非商用・商用利用を含めて基本的に無償でモデルを活用可能。一方、年間収入100万ドルを超える場合、Stability AIからエンタープライズライセンスを取得する必要があります。
画像生成がうまくいかない時の主な原因と対処法

Stable Diffusionで画像生成を行う際に、エラーが出ることがあります。
ここではエラーが出た際の主な原因と、原因ごとの対処法を解説します
原因1:VRAM不足
Stable DiffusionはGPU上で動作するため、十分なVRAM(ビデオメモリ)が必要です。一般的には6GB以上のVRAMが推奨されていますが、生成サイズやステップ数が大きいと8GB以上が望ましいこともあります。
Vramが不足している場合は、以下の対処法を試してみると良いでしょう。
- 生成画像の解像度を下げる(例:512×512に設定)
- batch sizeを1にすることで一度に処理するデータ量を減らす
- fp16(半精度)モードを有効化する(使用しているUIにオプションがある場合)
- それでも解決しない場合は、Google Colabなどのクラウド環境を利用するのも一つの手段です。
原因2:パスや権限の不備
モデルファイルが見つからない、スクリプトが実行できないなどのエラーは、ファイルの保存先パスが正しくない、あるいはアクセス権限が不足している場合に発生します。
パス参照にエラーが発生した場合は、下記の対象法を試してみてください:
- ファイルパスに日本語やスペースが含まれていないか確認
- モデルファイル(.ckptや.safetensors)が指定されたフォルダにあるかチェック
- スクリプトやフォルダに対して管理者権限(Windows)やsudo権限(Mac/Linux)で実行してみる
- 実行時に「Permission denied」エラーが出る場合は、chmod +xで実行権限を付与する
原因3:Mac/AMD GPU環境での動作問題
Stable DiffusionはNVIDIA製GPU(CUDA対応)に最適化されており、Mac(特にIntel Mac)やAMD GPUではそのままでは動作しない、あるいは非常に遅いという問題があります。
対処法としては、下記を試してみると良いでしょう:
- Macで動作させる場合は、Diffusers + MPS(Metal Performance Shaders)対応の実装を利用する(Hugging FaceのDiffusersが推奨)
- AMD GPUではPyTorchのROCmサポートを使う(対応が限定的で不安定なことが多い)
- 実行環境としては、Google ColabやKaggle Notebooksなど、NVIDIA GPUが使えるクラウドサービスを活用
まとめ - Stable Diffusionの今後の展望

Stable Diffusion 3.5は、高品質かつ多機能な画像生成能力を備え、ユーザーコミュニティ全体に新たな創造的可能性をもたらします。
ユーザーフレンドリーな実装方法、拡張性の高いAPI、コミュニティ主導のプラグイン開発などにより、Stable Diffusion 3.5は今後さらに進化し続けることが見込まれます。
是非その特徴を理解し、プライベートや仕事への導入を検討してみてはいかがでしょうか。
AIサービス導入のご相談は AI導入.com へ(無料)
AI導入.comでは、マッキンゼー・アンド・カンパニーで生成AIプロジェクトに従事した代表を中心に、日本・アメリカの最先端のAIサービスの知見を集めています。AIサービスの導入に関するご相談やお問い合わせを無料で承っております。ビジネスの競争力を高めるために、ぜひ以下のお問い合わせフォームよりご連絡ください。
