ローカルLLMとは?おすすめモデル12選と選び方・使い方を解説
近年、さまざまな大きな言語モデル(LLM)が登場していますが、その中でもローカルLLMが特に注目を集めています。
ローカルLLMは、特に個人情報やセキュリティ面で大きな利点があります。
この記事は、ローカルLLMの基本知識から実際の導入方法、さらに日本語に対応したモデル比較を解説sます。
ローカルLLMの基礎知識、導入方法、モデル比較に興味がある方はぜひ最後までお読みください。
ローカルLLMとは

imageFXで作成
ローカルLLMとは、利用者自身の機器上で動作する大規模言語モデルのことです。
ChatGPTのようなクラウドサービスとは違い、ネット接続なしで使うことができ、データが外部に送られないという特徴があります。
ローカルLLMモデルは、性能が限られた環境でも使えるように工夫されており、個人のパソコンやMac、スマホでも動かすことができます。
最近では日本語に対応したローカルLLMも増えており、多言語対応の選択肢が広がっています。
クラウド型LLMとの相違点

imageFXで作成
ローカルLLMとクラウド型LLMの最も大きな違いは、処理の場所とデータの扱い方にあります。
クラウド型LLMはOpenAIやGoogle、Anthropicなどの会社が管理するサーバーで処理が行われるため、常にネット接続が必要です。
一方、ローカルLLMは利用者の機器内で完結し、データが確実に保護されます。
また、クラウド型は一般的に高い性能を持つ一方、ローカルLLMは比較的小さなモデルが多く、GPUなどの機器性能に左右されます。
クラウド型LLMとローカルLLMを比較する際には、処理能力とプライバシーのどちらを優先するかが重要なポイントとなります。
ローカルLLMを導入するメリット

imageFXで作成
ローカルLLMを導入する最大のメリットは、データの所有権と個人情報を自分自身で管理できることです。
利用者のデータがクラウドに送られないため、機密情報を扱う業務や個人の情報を守りたい場合に適しています。
また、ネット接続に依存しないため、オフライン環境でも安定して使える点も魅力です。
以下では、セキュリティ、コスト、カスタマイズ性という3つのメリットについて詳しく解説します。
セキュリティの向上

imageFXで作成
ローカルLLMを利用することで、データセキュリティが大幅に向上します。
すべての処理がローカル環境で完結するため、機密情報や個人情報が外部サーバーに送られるリスクがなくなります。
企業の内部文書や個人的なメモなど、保護が必要な情報を扱う場合は特に効果的です。
また、ネット接続を必要としないため、ネットワーク経由の攻撃リスクも減少します。
ローカルLLMの作り方を学ぶ際は、セキュリティ面も重要な検討要素として考慮すべきです。
コスト削減
imageFXで作成
クラウド型LLMサービスは使った分だけ料金がかかる仕組みが一般的ですが、ローカルLLMは初期投資後の追加コストがほとんどありません。
頻繁に使う場合や大量のリクエストが必要な場合、長期的に見ると大幅なコスト削減につながります。
特にChatGPTのような商用サービスと比べると、定期購読料金が不要になる利点は非常に大きいです。
ただし、高性能なGPUが必要なモデルを導入する場合は、機器投資のコストバランスを考える必要があります。
ローカルLLM用のGPU選びは、コストと性能のバランスを左右する重要な要素です。
カスタマイズ性の向上

imageFXで作成
ローカルLLMの大きな魅力は、自分のニーズに合わせてカスタマイズできる点にあります。
特定の分野や用途に特化した調整や、独自データでのカスタマイズが可能です。
また、オープンソースのモデルを基にした改良も行えるため、特定の用語や専門知識を学習させるなど、自分だけの助手を作ることができます。
ローカルLLMモデルの選択肢は多様で、用途に応じた最適なモデルを選ぶことで、より効果的なAI活用が可能になります。
ローカルLLMの導入で直面する課題

imageFXで作成
ローカルLLMの導入には多くの利点がありますが、いくつかの課題も存在します。
特に初めて導入する場合は、適切な機器選び、専門知識の学習、そしてモデル管理の負担などが壁となることがあります。
以下では、ローカルLLM導入時によく直面する3つの主な課題について詳しく解説します。
高性能なハードウェアの必要性

imageFXで作成
ローカルLLMを快適に動かすには、十分な性能を持つ機器が欠かせません。
特に大きなモデルを動かす場合、高性能なGPUやメモリが必要となります。
最低限のローカルLLM性能としては、8GB以上のメモリとNVIDIA GTX 1060相当以上のGPUが推奨されます。
Macユーザーは Apple Siliconチップの高い効率性を活かせるため、ローカルLLMをMacでも比較的スムーズに動かせますが、モデルサイズによっては制限を受けることもあります。
スマホでの実行は限られており、軽いモデルに限定される場合が多いです。
専門知識の必要性

imageFXで作成
ローカルLLMの導入と運用には、ある程度の専門知識が求められます。
コマンドラインの操作、Pythonの基礎知識、GPUドライバーの管理など、初心者にとっては難しい要素が含まれています。
また、モデルの選定や最適な設定には、機械学習の基礎理解も役立ちます。
ローカルLLM一覧から自分に合ったモデルを選ぶためには、各モデルの特徴や必要条件を理解する学習コストがかかります。
しかし、最近ではグラフィカルな操作画面を持つツールも増えており、導入のハードルは徐々に下がってきています。
モデルの更新と管理の負担

imageFXで作成
クラウドサービスと違い、ローカルLLMではモデルの更新や管理は利用者自身の責任となります。
新しいバージョンが公開された際の更新作業や、複数のモデルを管理するための仕組み作りなど、継続的な運用コストが発生します。
また、大きなモデルではストレージ容量も考慮する必要があります。
特に日本語が得意なローカルLLM日本語モデルは更新頻度が高いことがあり、最新の性能を維持するための管理が求められます。
これらの負担を減らすためのツールや作業の流れを整えることが重要です。
おすすめのローカルLLMモデル12選

imageFXで作成
ローカルLLMの世界は急速に発展しており、さまざまなモデルが登場しています。
以下では、日本語対応や性能、必要性能などを考慮した代表的なローカルLLMモデルを12種類比較します。
用途や環境に応じて最適なモデルを選択する際の参考にしてください。
ローカルLLM比較の視点では、言語サポート、モデルサイズ、必要機器性能、特化分野などが重要な評価指標となります。
| モデル名 | サイズ | 日本語対応 | 性能特徴 | 特徴 |
|---|---|---|---|---|
| Llama | 38B-70B | 優 | 16GB RAM, GPU 8GB+ | Meta製、オープンソースモデルとして人気、バランスの良い性能 |
| Mistral AI | 7B-8x7B | 良 | 8GB RAM, GPU 4GB+ | 小サイズながら高性能、効率的な推論が可能 |
| Rinna-3.6B | 3.6B | 優 | 8GB RAM, GPU 4GB | 日本語特化モデル、少ない資源で高い日本語性能 |
| Vicuna | 7B-13B | 良 | 16GB RAM, GPU 6GB+ | 会話特化、応答の自然さが高い |
| ELYZA-japanese-Llama-2 | 7B-13B | 優 | 16GB RAM, GPU 8GB+ | 日本語に最適化された高性能モデル |
| GPT4All | 8B | 良 | 8GB | RAM, CPU可使いやすいグラフィカル操作画面付き |
| Phi-3 | 3.8B-14B | 良 | 8GB RAM, GPU 4GB+ | Microsoft製、サイズの割に高性能 |
| Gemma | 2B-7B | 良 | 8GB RAM, GPU 4GB+ | Google製、効率性に優れたモデル |
| RedPajama | 3B-7B | 可 | 8GB RAM, GPU 4GB+ | オープンソースのLlamaに近い性能 |
| TinyLlama | 1.1B | 可 | 4GB RAM, CPU可 | 超軽量モデル、スマホでも動作可能 |
これらのモデルはそれぞれ特徴が異なり、用途によって最適な選択肢も変わります。
日本語利用を重視するなら、Rinna-3.6BやELYZA-japanese-Llama-2などの日本語に特化したモデルがおすすめです。
資源が限られている環境では、TinyLlamaやPhi-3などの軽量モデルが適しています。
ローカルLLMをスマホで動かしたい場合は、特に小型モデルを選ぶ必要があります。
ローカルLLMの作り方・構築手順
imageFXで作成
ローカルLLMの構築は、適切な手順に従えば比較的スムーズに進めることができます。
ここでは一般的な構築手順を段階的に解説し、初心者でも取り組めるように解説していきます。
ローカルLLMの作り方の基本を理解することで、自分の環境に最適な設定が可能です。
環境準備からモデルの実行まで、5つのステップに分けて詳しく見ていきましょう。
環境準備

imageFXで作成
ローカルLLMを構築する最初のステップは、適切な環境を整えることです。
Windows、Mac、 Linuxでの適切な環境を見ていきましょう。
【Windows環境】
- 必要スペック:
- CPU: 最低でも4コア以上
- RAM: 16GB以上推奨(より大きなモデルには32GB以上)
- GPU: NVIDIA GPU(VRAM 6GB以上)推奨
- ストレージ: SSDの空き容量20GB以上
【Mac環境】
- 必要スペック:
- Apple Silicon搭載Mac (M1/M2/M3シリーズ)
- RAM: 16GB以上推奨
- ストレージ: SSDの空き容量20GB以上
【Linux環境】
- 必要スペック:
- CPU: 4コア以上
- RAM: 16GB以上
- GPU: NVIDIA GPU(CUDA対応)
- ストレージ: SSDの空き容量20GB以上
LLM実行フレームワークのインストール
環境準備ができたら、次はフレームワークのインストールを行います。
各環境のインストール方法を記載しております。

imageFXで作成
オプション1: llama.cpp (各プラットフォーム対応)
【Windowsの場合】
# Gitのインストール (まだの場合)
winget install --id Git.Git
# リポジトリのクローン
git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp
# ビルド (Visual Studioのコマンドプロンプトで実行)
cmake .
cmake --build . --config Release
【Macの場合】
# Homebrewを使用してツールをインストール
brew install cmake
# リポジトリのクローン
git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp
# ビルド
mkdir build && cd build
cmake ..
make -j4
【Linuxの場合】
# 必要なパッケージをインストール
sudo apt update
sudo apt install -y build-essential cmake
# リポジトリのクローン
git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp
# ビルド
mkdir build && cd build
cmake ..
make -j$(nproc)
オプション2: Ollama (オールインワンソリューション)
【Windowsの場合】
- Ollama公式サイトからインストーラーをダウンロード
- インストーラーを実行
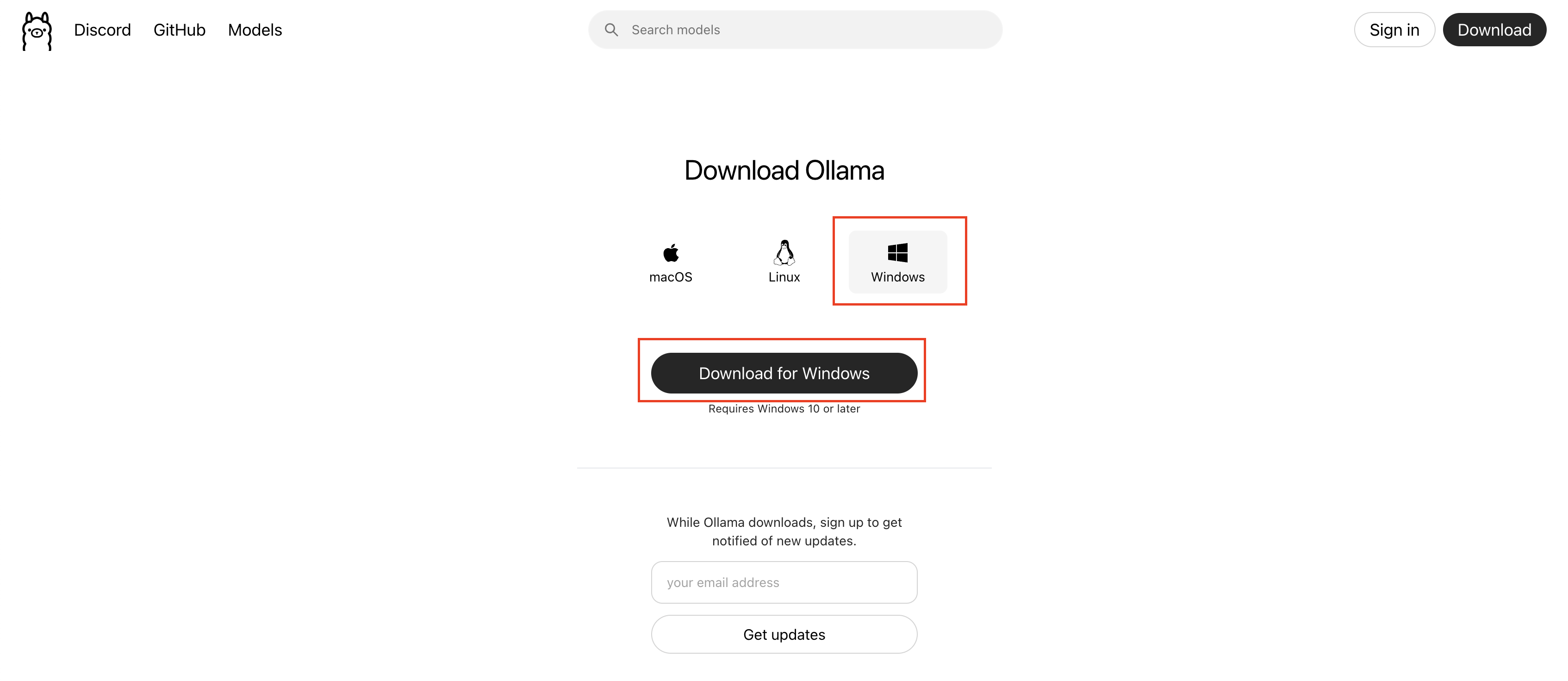
出典:ollama
【Macの場合】
brew install ollama
【Linuxの場合】
curl -fsSL https://ollama.ai/install.sh | sh
モデルのダウンロード・管理

imageFXで作成
【llama.cppの場合】
モデルは通常GGUF形式を使用します。
HuggingFaceなどから入手できます。
# llama.cppのディレクトリで実行
curl -L https://huggingface.co/TheBloke/Mistral-7B-Instruct-v0.1-GGUF/resolve/main/mistral-7b-instruct-v0.1.Q4_K_M.gguf -o models/mistral-7b-instruct-v0.1.Q4_K_M.gguf
【Ollamaの場合】
コマンドラインから簡単にモデルをダウンロードできます。
# Mistral 7Bモデルをダウンロード
ollama pull mistral
# Llama 2 7Bモデルをダウンロード
ollama pull llama2
Webインターフェース(オプション)

imageFXで作成
コマンドラインでの操作に慣れていない場合は、WebUIを導入すると使いやすくなります。
【オプション1: llama.cpp + web UI (text-generation-webui)】
インストール手順
# リポジトリをクローン
git clone https://github.com/oobabooga/text-generation-webui.git
cd text-generation-webui
# 必要なパッケージをインストール
pip install -r requirements.txt
# webUIの起動 (llama.cppバックエンドを使用)
python server.py --model /path/to/your/model.gguf --loader llama.cpp
【オプション2: Ollama + Web UI】
インストール手順
# Dockerを使用する場合
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway --name ollama-webui --restart always ghcr.io/ollama-webui/ollama-webui:main
これにより、ブラウザからLLMを操作できるインターフェースが立ち上がります。
ChatGPTのような使い勝手を実現でき、初心者にも扱いやすくなります。
モデルの実行と推論

imageFXで作成
すべての準備が整ったら、いよいよモデルを実行します。
【llama.cppでの実行例】
コマンドライン実行
# llama.cppディレクトリで
./main -m models/mistral-7b-instruct-v0.1.Q4_K_M.gguf -n 256 -p "こんにちは、あなたの名前は?"
パラメータ説明
-m: モデルファイルのパス-n: 生成するトークン数-p: プロンプト(質問や指示)
【Ollamaでの実行例】
コマンドライン実行
# 基本的な使用法
ollama run mistral "こんにちは、あなたの名前は?"
# パラメータ付きの実行
ollama run mistral --temperature 0.7 "京都で人気の観光スポットを5つ教えてください。"
【APIを使用した実行例】
curl -X POST http://localhost:11434/api/generate -d '{
"model": "mistral",
"prompt": "こんにちは、あなたの名前は?",
"stream": false
}'
ローカルLLMモデルごとに最適なパラメータは異なるため、試しながら自分好みの設定を見つけることが大切です。
デバイス別ローカルLLMの実行方法

imageFXで作成
ローカルLLMはさまざまな機器で実行可能ですが、機器によって設定方法や最適なモデル選択が異なります。
ここでは、パソコンとモバイル機器それぞれでのローカルLLM実行方法を解説します。
機器の特性を理解し、最適な環境を構築することで、より効率的にローカルLLMを活用できるようになるでしょう。
PC(Windows / macOS / Linux)で実行する際のポイント
imageFXで作成
PCでのローカルLLM実行は最も一般的で、選択肢も豊富です。
Windowsでは、WSL2を利用するか、ネイティブアプリケーションを使用する方法があります。
macOSでは、Apple SiliconチップのMetal APIを活用することでGPUがなくても高速処理が可能です。
ローカルLLMをMacで使う強みは、この統合環境による効率性にあります。
Linuxは最も柔軟な環境で、多様なモデルとフレームワークに対応しています。
グラフィカルアプリケーションとしてはLM Studio、Ollama、KoboldCPPなどが人気で、初心者にも扱いやすい操作画面です。
モバイルデバイス(iOS / Android)で実行する際のポイント

imageFXで作成
モバイル機器でもローカルLLMの実行が可能になってきています。
iOSでは「Llama in Your Pocket」や「Mantis」などのアプリが、Androidでは「MLC LLM」や「Llama 2 Turbo」などが利用できます。
ローカルLLMをスマホで実行する場合は、モデルサイズに特に注意が必要です。
多くの場合、1B〜2B程度の小型モデルに限定されますが、最新の高性能スマートフォンでは7Bクラスのモデルも動作可能になっています。
バッテリー消費と発熱には注意し、長時間使用する場合は充電しながらの使用をおすすめします。
まとめ

imageFXで作成
ローカルLLMは、個人情報保護、コスト削減、カスタマイズ性の向上など、多くの利点を提供する技術です。
この記事では、基本概念から具体的な導入方法、そして機器別の実行方法まで幅広く解説しました。
ローカルLLMの世界は急速に発展しており、日々新しいモデルやツールが登場しています。
初心者の方は、OllamaやLM Studioなどの使いやすいツールから始めることをおすすめします。
専門的知識がある方は、llama.cppなどを使ってカスタマイズすることも可能です。
ローカルLLM一覧から自分の環境と目的に合ったモデルを選び、AI技術を活用していきましょう。
