Difyで始めるRAG構築の仕方を徹底解説
ここでは、オープンソースで提供されているLLMプラットフォームであるDifyを使いながら、RAG(Retrieval-Augmented Generation)を実装する方法を解説します。具体的な手順や最適化のポイントを詳しく紹介し、社内文書検索やFAQボットなど幅広いユースケースに応用できる知識を提供します。
また、弊社では「AI使いたいが、どのような適用領域があるのかわからない…」「AI導入の際どのサービス提供者や開発企業を組めばいいかわからない…」という事業者の皆様に、マッキンゼーやBCGで生成AIプロジェクトを経験したエキスパートが完全無料で相談に乗っております。
興味のある方はぜひ以下のリンクをご覧ください:
代表への無料相談はこちら

AI導入.comを提供する株式会社FirstShift 代表取締役。トロント大学コンピューターサイエンス学科卒業。株式会社ANIFTYを創業後、世界初のブロックチェーンサービスを開発し、東証プライム上場企業に売却。その後、マッキンゼー・アンド・カンパニーにコンサルタントとして入社。マッキンゼー日本オフィス初の生成AIプロジェクトに従事後、株式会社FirstShiftを創業。
RAG 概要説明
この章では、RAGの基本的な仕組みとメリットについて紹介します。RAGを導入するメリットや、なぜ外部データを組み合わせるとLLMがより賢くなるのかを知ることができます。
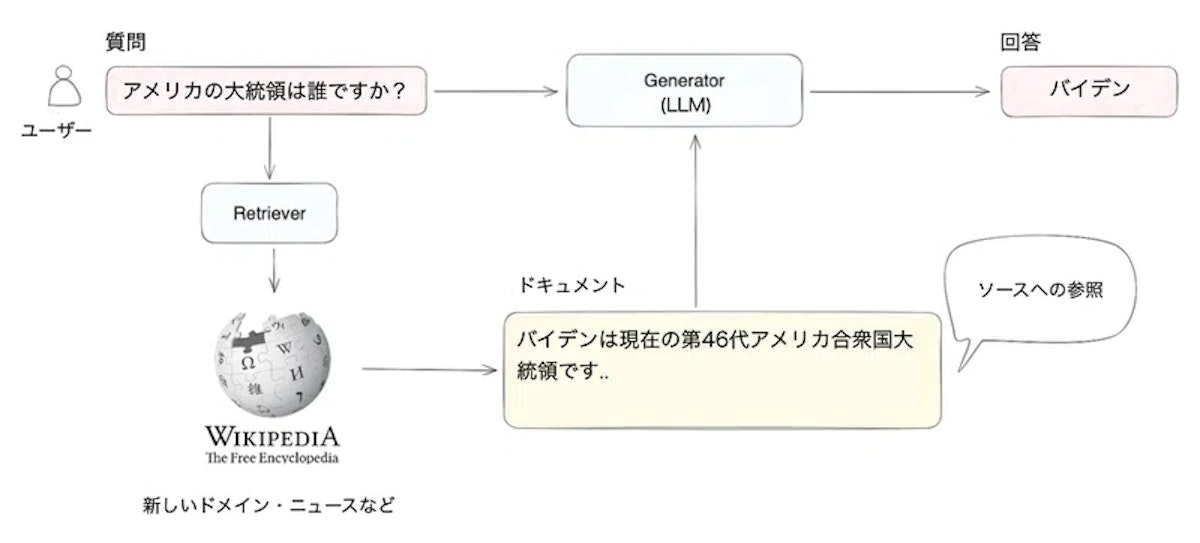
RAG(Retrieval-Augmented Generation) とは、外部の知識ベース(ベクトルデータベースなど)を活用して大規模言語モデルが回答を生成する手法です。
ベクトル化された文書を検索し、ユーザーの質問に合う文書チャンクを取り出してからLLMに渡すことで、最新情報や専門的な知識が反映された回答を得ることができます。
こうした手法は、ハルシネーション(幻覚)を抑制し、信頼性の高い回答を生成する上で非常に有効です。
上記の図では、ユーザーが「アメリカ大統領は誰ですか?」と質問をするとLLMが答えるのではなく外部のベクトル化されたデータをもとに回答しています。
Dify 概要説明
この章では、Difyがどのような特徴を持つオープンソースLLMプラットフォームなのかを説明します。Difyを使うメリットや、主な機能を理解することができます。
Dify(ディファイ)はオープンソースの生成AIアプリ開発プラットフォームです。
プログラミング不要のノーコード操作で、高度なAIチャットボットやAIエージェント、さらにはワークフロー型のバッチ処理アプリまで直感的に作成できます。Difyはソースコードが公開されたOSSであり、自社サーバーにセルフホスティングすることも可能です。
そのためデータを外部クラウドに送信せずに済み、必要に応じてオープンソースのLLM(大規模言語モデル)を組み合わせて社内環境だけで完結させることもできます。これにより、生成AI利用時に問題視されがちな機密データの漏洩リスクを低減できます。
Difyの名称は「Define(定義する)+ Modify(改良する)」に由来し、「Do it for you(あなたのためにやる)」の意味も込められています。主要な特徴として、以下のような機能が統合されています
複数の主要LLMをサポート
OpenAIのGPTシリーズはもちろん、AnthropicのClaudeやGoogleのPaLM (Gemini) など様々なモデル、さらにローカルのLLMにも対応可能。モデルごとのAPIキーを設定するだけで利用できます。
プロンプトのオーケストレーション
対話の流れや処理手順(ワークフロー)を視覚的に設計できるインターフェースを備えます。ドラッグ&ドロップでブロック(ノード)をつなぎ、分岐やループなども設定可能なビジュアルフローエディタになっています。
RAG(Retrieval-Augmented Generation)対応
文書やナレッジデータを活用するためのエンジンを内蔵し、「ナレッジ」機能として実装されています。アップロードしたファイルや外部データをベクトル埋め込みし、質問に関連する情報を検索して回答に反映できます。ベクトル検索だけでなくキーワード考慮のハイブリッド検索も選択でき、EmbeddingモデルもOpenAIやCohere、AWSなど複数から選べます。
AIエージェント機能

ユーザーの問いに応じて外部ツールの呼び出しや複数タスク実行を行うエージェントを構築できます。例えばウェブ検索や画像生成などのツールを組み合わせ、より複雑な指示に対応することも可能です。
低コードのワークフロー
ユーザー入力なしで定期実行や一連のタスク処理を自動化するワークフローを作成できます。これは現在プレビュー機能ですが、チャットフロー同様のノード操作で、定時バッチ処理などユーザー操作なしのシナリオにも対応します。
使いやすいUIとAPI:
直感的なユーザーインターフェースで誰でも操作できる一方、開発者向けにはRESTfulなAPI提供もあり、外部システム統合やカスタムUI開発も容易です。
RAG 重要ポイント

この章では、RAGにおける主要な概念や、なぜDifyを使うことでRAGが簡単に実装できるのかを紹介します。RAGの構成要素やワークフローも理解できます。
RAGの概念とメリット
RAGの最大のメリットは、LLMでは学習しきれていない最新情報や専門知識を追加で取り込める点です。
ユーザーが投げかけるクエリを一度Embeddingして、類似度検索により関連文書を取り出し、LLMに補足情報として与えます。
これによって、より正確で新しい情報に基づく回答が可能になります。
RAGの構成要素とワークフロー
RAGシステムは大まかに下記の流れで動きます。
- ユーザーの質問をEmbeddingし、ベクトルデータベースで検索
- 上位候補の文書チャンクを取得
- LLMにチャンクをコンテキストとして与え、回答生成
- ユーザーに回答を返却
Difyでは、こうした流れをGUIを通して手早く構築できます。
幻覚(ハルシネーション)を抑える仕組み
LLMは自信をもって存在しない情報を答えることがありますが、RAGでは検索結果をプロンプトに含めるため、幻覚を大幅に抑えることができます。
また、Difyのシステムプロンプトやハイブリッド検索をうまく活用すると、より高い正確性を担保しやすくなります。
Dify ナレッジ作成
この章では、具体的にDify上でナレッジベース(RAG)を作るステップを紹介します。アップロードからインデックスの設定、Embeddingモデルの指定までの手順を理解できます。
1.「ナレッジの作成」から始めることができます。
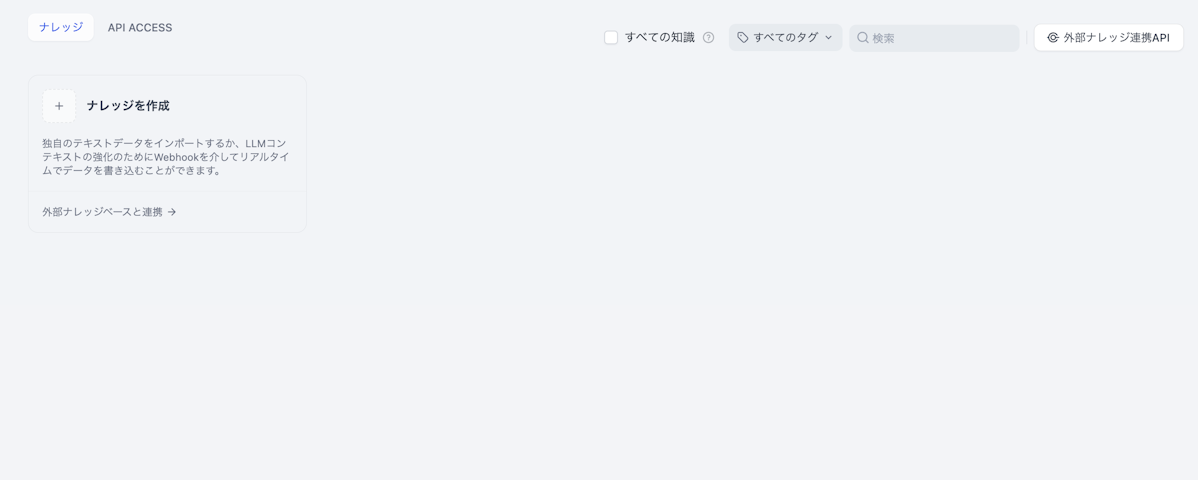
2.PC上のファイルかNotion上のデータ・WEBサイトのデータをナレッジに用いることができます。
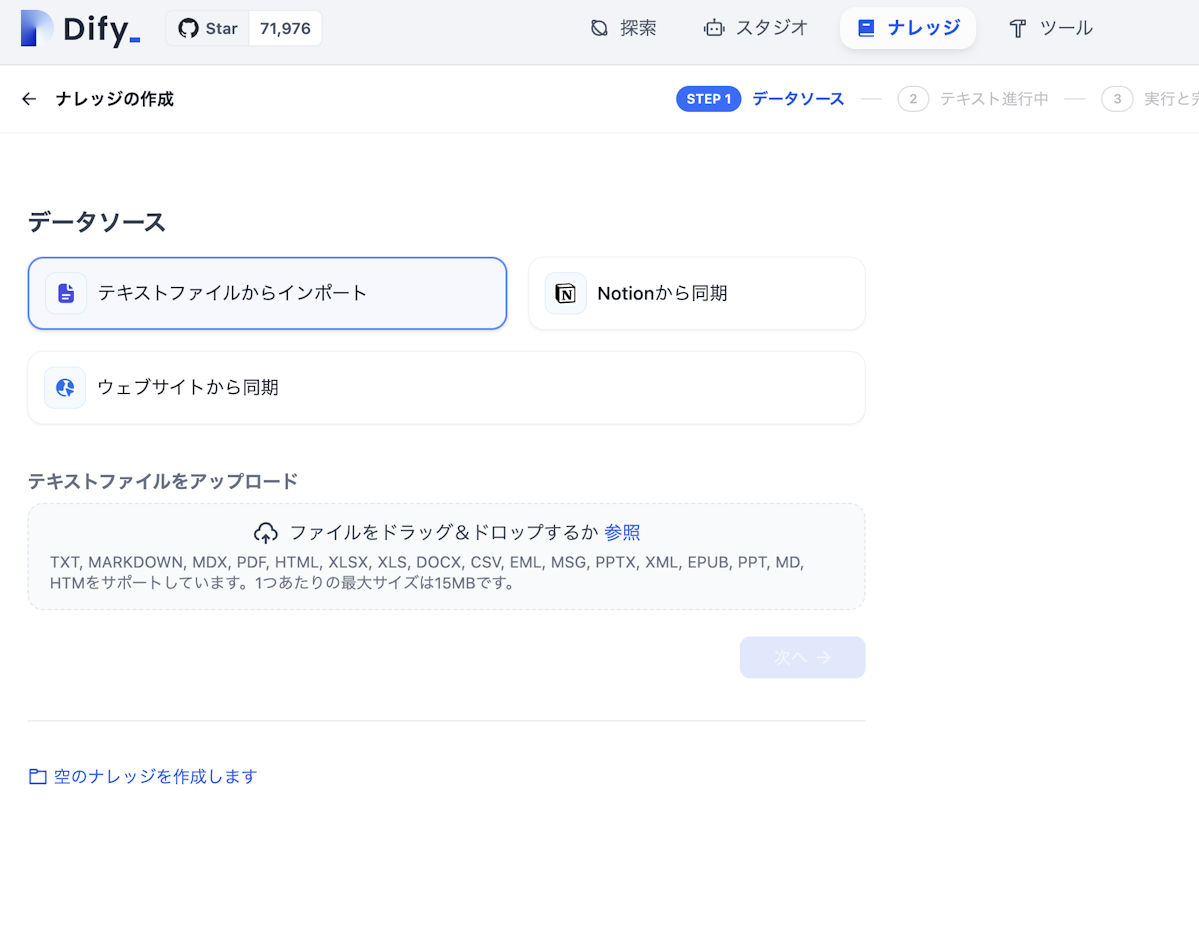
3.チャンクや区切れ文字を設定します。
ここでは、意味的なかたまりごとにチャンクが分かれるように区切れ文字を設定する必要があります。また、場合によっては意味ごとに適切に区切ることができるように事前にファイルを修正する必要があります。
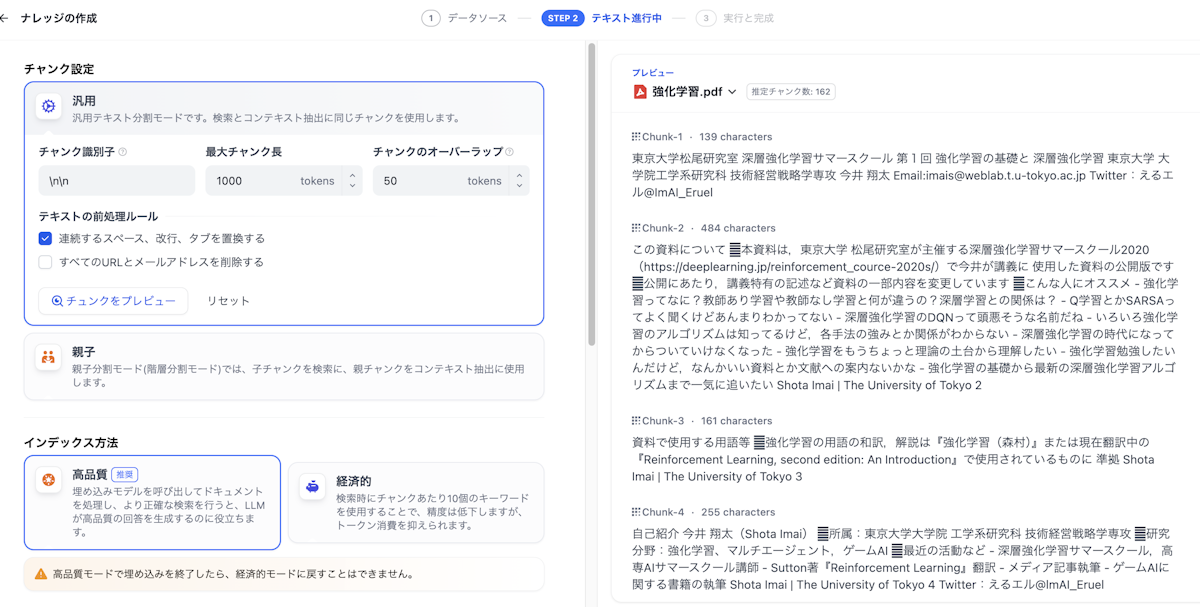
4.インデックス方法を選択します。
インデックス方法としては高品質(ベクトル検索)や経済的(キーワードのみ)が選択可能で、ハイブリッド検索の設定もできます。
EmbeddingモデルやRe-rankモデルをCohereやOpenAIで設定すれば、複数言語や専門用語にも柔軟に対応できます。
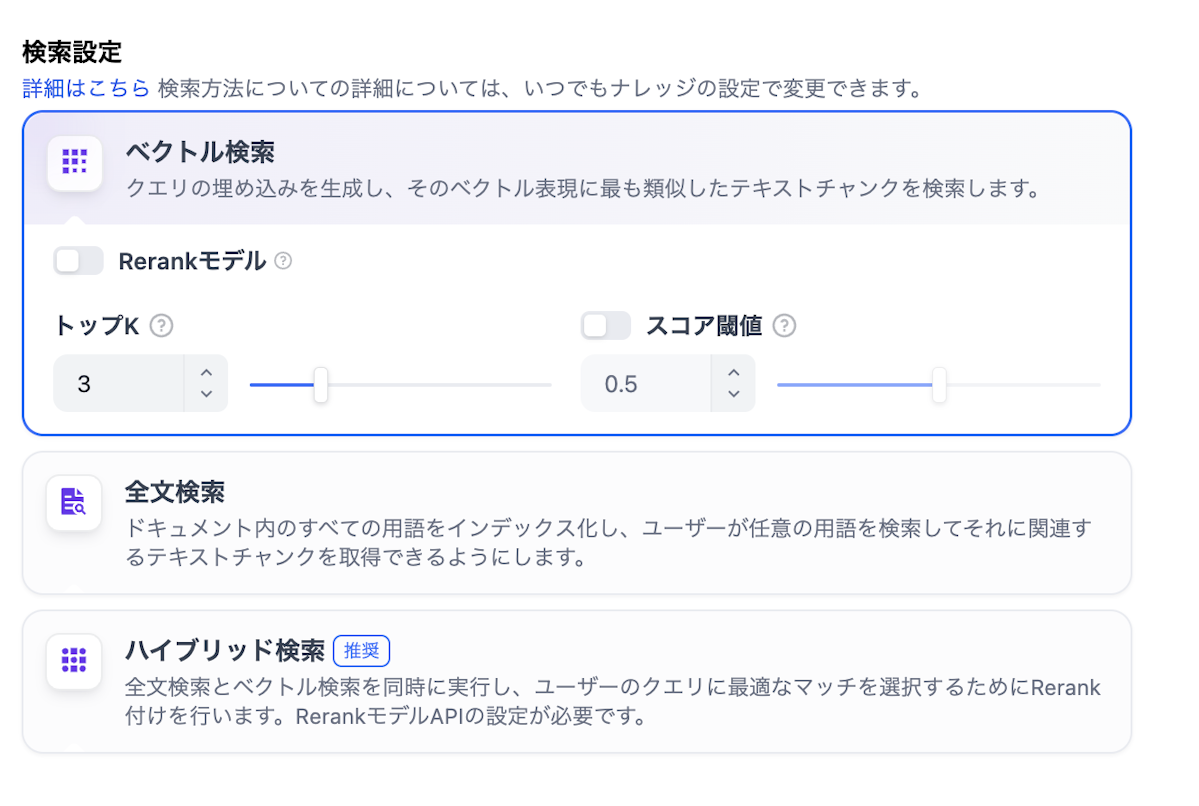
5.処理が終わると、検索テストから精度をチェックすることができます。
うまくいかない場合はチャンク長やオーバーラップを修正してください。
検索精度と回答精度

この章では、Embeddingモデルの選び方やハイブリッド検索、プロンプトエンジニアリングなど、RAGの精度を高めるための具体的な手法を知ることができます。
検索精度向上のベストプラクティス
より高性能なEmbeddingモデルを使うことで、類似度検索の精度が上がります。
また、チャンクサイズを適切にし、ハイブリッド検索やRe-rankモデルを活用することで、関連性の高い文書を漏れなく検索できます。
データの重複や古い情報を定期的に整理することも重要です。
応答品質を向上させるプロンプトエンジニアリング
システムプロンプトで「与えられた情報のみで回答する」と指示すれば、幻覚の抑制に役立ちます。
回答フォーマットを指定し、必要に応じてFew-shot例示を追加すると、自然な文章が生成されやすくなります。
さらに、LLMのバージョン(GPT-4など)を検討することで回答の正確性も上げられます。
Dify 今後の展望

この章では、Difyが今後どのように機能拡張していくのか、ロードマップやコミュニティ動向を説明します。最新機能の開発状況も把握できます。
DifyはNotionやGitHubリポジトリとのデータ同期など、連携強化のアップデートを続々と行っています。
Parent-Child Retrievalの導入やマルチモーダルへの対応も検討されており、将来的にはさらに幅広いRAGシステムを簡単に構築できるようになる見込みです。
コミュニティも活発で、エンタープライズ向けの機能やプラグインなどの開発も進められています。
まとめと次ステップ
Difyを利用すれば、RAGの構築がノーコードに近い手順で可能になり、外部知識を融合した高度な回答を簡単に作れます。
複数の埋め込みモデルやベクトルDBへの対応も豊富で、大規模データやセキュア環境でも運用しやすいです。
今後は、クラウド版やオンプレ導入などの選択肢を検討し、自社のニーズに合った環境でテストしてみるとよいでしょう。
精度向上のためのプロンプトエンジニアリングやRe-rankモデルの活用も忘れずに行いながら、LLMの可能性をぜひ広げてみてください。
AIサービス導入のご相談は AI導入.com へ(完全無料)
- マッキンゼー出身の代表による専門的なアドバイス
- 日本・アメリカの最先端AIサービスの知見を活用
- ビジネスの競争力を高める実践的な導入支援