【徹底解説】LoRAとは?仕組みや作り方まで完全ガイド
「LoRA(Low-Rank Adaptation)」という技術は、巨大なAIモデルをわずかな追加パラメータのみで低コストにカスタマイズできる方法として注目されています。近年では大規模言語モデル(LLM)はもちろん、Stable Diffusionのような画像生成モデルでも盛んに活用されており、個人開発から企業の商用利用まで幅広い場面で導入が進んでいます。
本記事では、LoRAの仕組みや特長、具体的な導入手順、他の微調整手法(DreamBoothやTextual Inversionなど)との比較、最新の拡張研究(QLoRAなど)までを網羅的に解説します。また、Stable Diffusionにおける具体的な実装例から著作権や商用利用の留意点まで、幅広くカバーしています。
また、弊社では「AI使いたいが、どのような適用領域があるのかわからない…」「AI導入の際どのサービス提供者や開発企業を組めばいいかわからない…」という事業者の皆様に、マッキンゼーやBCGで生成AIプロジェクトを経験したエキスパートが完全無料で相談に乗っております。
興味のある方はぜひ以下のリンクをご覧ください:
代表への無料相談はこちら

AI導入.comを提供する株式会社FirstShift 代表取締役。トロント大学コンピューターサイエンス学科卒業。株式会社ANIFTYを創業後、世界初のブロックチェーンサービスを開発し、東証プライム上場企業に売却。その後、マッキンゼー・アンド・カンパニーにコンサルタントとして入社。マッキンゼー日本オフィス初の生成AIプロジェクトに従事後、株式会社FirstShiftを創業。

1. LoRAとは?
LoRA(Low-Rank Adaptation)は、既に学習済みの巨大なAIモデル(Stable DiffusionやGPTなど)に対して、「差分」だけを学習させる技術です。
通常、大規模モデルを微調整するには、多数のパラメータを更新する必要があり、大変な計算リソースと時間がかかります。しかしLoRAを使うと、極めて小さな追加パラメータだけを学習することで、新しいスタイルやキャラクターなどをモデルに覚えさせることが可能です。
- ベースモデルはそのまま
→ 元のパラメータをいじらないので、既存機能を壊す心配が少ない。 - 追加パラメータは軽量
→ 出来上がるLoRAファイルは数MB〜数十MB程度。インターネットでの共有や使い回しが容易。
2. LoRAのメリット:なぜ使われるの?
- 学習コストが低い
普通にモデルを再学習しようとすると、数GB以上のVRAMが必要だったり、何時間もかかったりします。LoRAなら、VRAMや計算量を大幅に節約可能です。 - 差分ファイルが超コンパクト
モデル全体を再保存すると数GBの大きさになりますが、LoRAは「追加情報」だけなので数MB程度で済みます。配布もしやすく、ストレージの負担が軽減されるのもポイントです。 - 元のモデルの知識を壊しにくい
既存の能力(多彩なスタイル・構図など)をそのまま活かしつつ、新しい概念を学習できます。破滅的忘却(元々の知識が消える現象)が起こりにくいといわれています。 - 複数のLoRAを組み合わせられる
例えば「キャラクターAのLoRA」と「水彩画風LoRA」を同時に適用し、キャラクターAを水彩画テイストで描く…といったことが手軽にできます。
3. LoRAの仕組み:専門用語も簡単解説
LoRAが「元モデルをほぼ変えずに新たな知識を注入」できるのは、低ランク行列を使うからです。
- 低ランク行列って何?
→ 「行列」とは、数字を格子状に並べたもの。LoRAでは、この行列を小さく切り分けたり圧縮したりして、最終的に元モデルに加える「差分」を表現します。
→ 例えるなら、大きな地図を全部描き直すのではなく、必要な部分だけを小さな「切り貼りパーツ」で追加していくイメージです。 - 元の重み(パラメータ)は凍結
→ LoRAの学習時は、ベースモデル側の重みを変えず、LoRAの小さな行列だけ更新します。
→ だから学習コストが軽いのに、ちゃんと新しい知識を加えられるのです。
4. LoRAを使った画像生成の応用例
LoRAは特にStable Diffusionの世界で大きく普及しています。例えば:
- 特定キャラクターの再現
数枚の画像だけでキャラの顔や服装の特徴を学習し、プロンプトで「LoRA名」を指定すると、そのキャラが登場するイラストを自由に生成できます。 - 画風・スタイルの学習
有名画家の作風や、アニメ風、写真風などを取り込むことが可能。ベースモデルが全く知らないスタイルを、数日で覚えさせるよりはるかに手軽です。 - 背景だけを強化するLoRA
「暗いシーンが苦手」「細部が甘い」などを補正するLoRAもコミュニティで多数共有されています。既存のモデルを崩さずに特定の欠点を改善できます。 - 複数LoRAの合成
同時適用で「キャラLoRA × 背景強化LoRA × アートスタイルLoRA」といった柔軟な組み合わせも可能で、独自の世界観を生み出せます。
5. LoRAの学習・導入方法(ステップ解説)
ここではStable Diffusionを例に、LoRAをどうやって作ったり使ったりするか流れをざっくりご紹介します。具体的な実践例は後述いたします。
- データ収集
- 学習させたい画像(スタイルやキャラなど)を数枚〜数十枚用意し、それぞれに説明文(キャプション)をつける。
- ベースモデルを用意
- Stable Diffusion 1.5や2.1、またはカスタム派生モデルなど。LoRAは学習したモデルのバージョンに依存するので注意が必要です。
- LoRA学習スクリプトを実行
- 「Kohya氏のLoRA学習ツール(後述)」や「AUTOMATIC1111のDreamBooth拡張」などを使えばGUIで簡単にLoRAを作れます。
- GPUがあるPCやGoogle Colabなどで実行。VRAM要件はフル微調整よりずっと小さいです。
- LoRAファイルの出力
.safetensors形式などで数MB〜数十MBの差分ファイルが出来上がります。
- 適用してみる
- 「AUTOMATIC1111 Web UI」なら、生成時のプロンプトに
<lora:ファイル名:強度>と書くだけでOK。 - Hugging FaceのDiffusersを使う場合は
load_lora_weightsという関数でロードし、ベースモデルに差分を適用します。
- 「AUTOMATIC1111 Web UI」なら、生成時のプロンプトに
LoRAの学習に関する記事はこちら
6. 他の手法(DreamBooth・Textual Inversionなど)との違い
- DreamBooth
- モデル全体を再学習するためVRAMや計算時間が多く必要。
- 高品質だが数GBのモデルを再保存することになり、配布しづらい。
- LoRAは必要な箇所だけ学習・差分保存なので軽量。
- Textual Inversion
- テキストエンコーダ(言葉の埋め込み)だけを学習する手法。
- ファイルサイズは数KB〜数十KBと超軽量だが、表現力はLoRAより狭い傾向。
- LoRAはモデル内部の重みにまで影響できるので、新しい描写をより強力に加えられる。
7. LoRAの今後と展望
LoRAは登場以降、画像生成AIのデファクトスタンダードになりつつあります。さらに近年は
- QLoRA:モデルを4bitに圧縮してさらにLoRA微調整する手法
- LyCORIS:畳み込み層やHadamard積などLoRAの拡張版
といったバリエーションも増え、より少ないメモリで高精度なチューニングが可能になりつつあります。
また、大規模言語モデル(ChatGPTのような会話AI)に対してもLoRAを使う動きが広がっています。企業レベルでの商用利用だけでなく、個人が自分だけのカスタムAIを作る時代もそう遠くありません。
8. 【実践例】Kohya's GUIでLoRAを実行する
ここでは、Mac環境を前提として、Kohya’s GUIを活用しLoRAを作成する流れを解説します。Stable Diffusion WebUI(AUTOMATIC1111)の導入、学習用データの準備方法、拡張機能の使い方などを含めた一連の手順をまとめているので、参考にしてみてください。
8-1: 事前準備
◆ Homebrewの導入
-
ターミナルを起動したら、以下のコマンドを貼り付けてHomebrewを入れます。
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)" -
インストールが終わったら、
.zshrcや.bashrcなどにパスを追記してください。export PATH="$PATH:/opt/homebrew/bin/"
8-2: Stable Diffusion Web UI(AUTOMATIC1111)のインストール
◆ 必要ライブラリのインストール
Homebrewが使用できるようになったら、以下を実行して必要なツールを準備します。
brew install cmake protobuf rust python@3.10 git wget
◆ リポジトリのクローンと起動
-
任意のフォルダ内でリポジトリを取得します。
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui -
クローン後、ディレクトリに移動してWebUIを実行しましょう。
cd ~/stable-diffusion-webui ./webui.sh -
ターミナルに表示されたURL(例:
http://127.0.0.1:7860)をブラウザで開けば、Stable Diffusion WebUIにアクセスできます。
8-3: Kohya's GUIのインストール
◆ 仮想環境の作成と有効化
システム環境と分離したい場合、以下のように仮想環境を設定します。
python -m venv venv
source venv/bin/activate
◆ セットアップ手順
-
リポジトリを取得します。
git clone https://github.com/bmaltais/kohya_ss.git -
クローン先のディレクトリに入り、セットアップを開始します。
./setup.sh
必要なPythonモジュールをまとめてインストールするには、以下のコマンドを利用してください。
pip install -U -r requirements.txt
◆ 起動
セットアップ後、GUIは下記のスクリプトで起動できます。
./gui.sh
8-4: Stable Diffusionで学習用データを用意する
◆ フォルダ構成
-
Kohyaのディレクトリ直下に、以下の3つのフォルダを作るとわかりやすいです。
├── outputs ├── training └── training_archive -
trainingフォルダ内に、学習データ用のサブフォルダを作成します。名前は[学習の繰り返し回数]_[トリガープロンプト](例:
25_cat)にしておくと管理しやすくなります。 -
学習に使う画像は20~30枚程度が目安で、ファイル名を連番(
cat_1.png,cat_2.pngなど)にしておくのがおすすめです。縦横比が混在していても問題ありません。
Kohya/
├── outputs/
├── training/
│ └── 20_robot/
│ ├── cat_1.png
│ ├── cat_1.txt
│ ├── cat_2.png
│ ├── cat_2.txt
│ ├── cat_3.png
│ ├── cat_3.txt
│ ├── cat_4.png
│ └── cat_4.txt
└── training_archive/
8-5: KohyaでLoRAを作成する
◆ LoRAタブを選択
Kohya’s GUIを立ち上げたら、画面上部のメニューからLoRA > Trainingをクリックします。DreamboothタブではなくLoRAタブを使う点に注意してください。
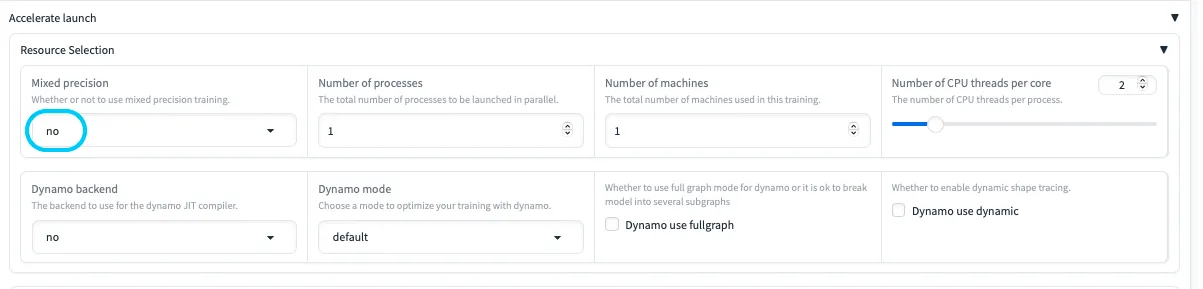
◆ Accelerate設定
- MixedPrecisionが
fp16やbf16だと、MPS環境でエラーを起こしがちです。noに変更しておくと安心です。 - Dynamo関連の設定は必要に応じて調整しましょう。
◆ Models設定
- 学習に使うベースモデルを指定します。
- Mac環境の場合、
runwayml/stable-diffusion-v1-5など比較的軽めのモデルがトラブルが少なくおすすめです。 - 出力ファイル形式(
Save trained model as)はsafetensorsにすると互換性が保ちやすいです。
◆ Folders・Dataset Preparation
- Output directory for trained model: 学習が完了したファイルの置き場所。
- Training images: 先ほど用意した学習画像の「親ディレクトリ」を設定。
- 学習の繰り返し回数(Repeat)は、フォルダ名に付けた数字をここに入れておくと整理しやすくなります。
◆ 主なパラメータ
- LoRA type: 通常はStandard。
- Train batch size: 2~4程度からスタート。
- Epoch: 2回程度で様子を見つつ、必要に応じて増やす。
- Optimizer:
AdamWが定番(CUDAに依存する8bit系はMPS環境だと非対応)。 - Learning rate: 0.0001あたりが無難な初期値。
- Max resolution: 512×512か640×640が一般的。
- Enable buckets: 画像サイズが異なる場合に有効にすると便利。
以上の設定後、実際に学習を始めてみましょう。まずは小規模(低バッチサイズや少ないエポック)で問題なく動作するか確認したうえで、本格的にパラメータを増やして精度を追求すると効率的です。
Pythonを使ったLoRAの作成方法はこちら
まとめ
LoRAは、モデルの一部だけを低ランク行列で学習・付け足す発想により、少ないリソースでも柔軟にモデルを拡張できる技術です。
- 本体のサイズを大きく変えずに微調整が可能
- 生成物のテイストやキャラクターをピンポイントで学習できる
- 複数のLoRAを組み合わせて使えるので表現の幅が広い
Stable Diffusionユーザーにとっては欠かせない方法になりつつあります。ぜひ本手順を参考にして、あなた独自のLoRAを作り、さらに充実したAI画像生成を楽しんでみてください。
AIサービス導入のご相談は AI導入.com へ(完全無料)
- マッキンゼー出身の代表による専門的なアドバイス
- 日本・アメリカの最先端AIサービスの知見を活用
- ビジネスの競争力を高める実践的な導入支援